The AI4Media project developed a Roadmap on AI technologies and applications for the Media that aims to provide a detailed overview of the complex landscape of AI for the media industry.
This Roadmap:
- analyses the current status of AI technologies and applications for the media industry;
- highlights existing and future opportunities for AI to transform media workflows, assist media professionals, and enhance the user experience in different industry sectors;
- offers useful examples of how AI technologies are expected to benefit the industry in the future; and
- discusses facilitators, challenges, and risks for the wide adoption of AI by the media.
The roadmap comprises 35 white papers discussing different AI technologies and multimedia applications, use of AI in different media sectors, AI risks for the society and economy, legal and ethical aspects and latest EU regulations, AI datasets, benchmarks & open repositories, opportunities in the time of the pandemic, environmental aspects and many more.
The AI4Media Roadmap offers an in-depth analysis of the AI for Media landscape based on a multi-party, multi-dimensional and multi-disciplinary approach, involving the AI4Media partners, external media or AI experts but also the AI research community, and the community of media professionals at large. Three main tools have been used to describe this landscape, including:
- a multi-disciplinary state-of-the-art analysis involving AI experts, experts on social sciences, ethics and legal issues, as well as media industry practitioners;
- a public survey targeted at AI researchers/developers and media professionals; and
- a series of short white papers on the future of AI in the media industry that focus on different AI technologies and applications as well as on different media sectors, exploring how AI can positively disrupt the industry, offering new exciting opportunities and mitigating important risks.
Based on these tools, we provide a detailed analysis of the current state of play and future research trends with regard to media AI (short for “use of AI in media”), which comprises the following parts.
State-of-the-art analysis of AI technologies and applications for the media. Based on an extensive analysis of roadmaps, surveys, review papers and opinion articles focusing on the trends, benefits, and challenges of the use of AI, we provide a clear picture of the most transformative applications of AI in the media and entertainment industry. Our analysis identifies AI applications that are already having or can have a significant impact in most media industry sectors by addressing common needs and shared aspirations about the future as well as AI technologies that hold the greatest potential to realise the media’s vision for AI.
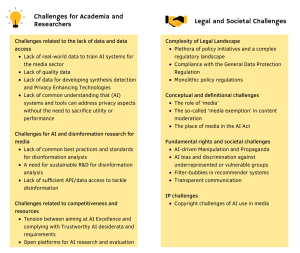
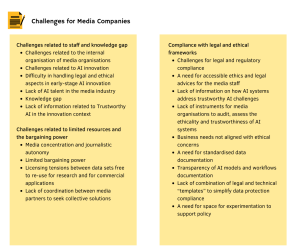
Discussion of social, economic and ethical implications of AI. Complementing the previous state-of-the-art analysis, which highlights AI’s potential for the media industry from a technology and practical application point of view, this analysis dives into the social and ethical implications of AI, offering the point of view of social scientists, ethics experts and legal scholars, based on an extensive literature review of both industry reports and scholar articles. The most prevalent societal concerns and risks are identified, including bias and discrimination; media (in)dependence; unequal access to AI; privacy, transparency, accountability and liability; etc. In addition, we identify practices to counteract the potential negative societal impacts of media AI.
EU policy initiatives and their impact on future AI research for the media. We provide an overview of EU policy initiatives on AI, focusing on initiatives having a clear focus on the media industry. We discuss both policy (non-binding provisions) and regulatory initiatives (leading to the adoption of binding legal provisions), including the Digital Services Act, the AI Act, the Code of Practice on disinformation, the Proposal on transparency and the targeting of political advertising and more.
Analysis of survey results. Two online surveys were launched: i) a public survey aiming to collect the opinions of the AI research community and media industry professionals with regard to the benefits, risks, technological trends, challenges and ethics of AI use in the media industry (150 respondents from 26 countries); and b) a small-scale internal survey addressed to the consortium, aiming to collect their opinions on the benefits and risks of media AI for society and democracy.
Main AI technology & research trends for the media sector. Based on the results of the state-of-the-art analysis, we highlight the potential of specific AI technologies to benefit the media industry, including reinforcement learning, evolutionary learning, learning with scarce data, transformers, causal AI, AI at the edge, bioinspired learning, quantum computing for AI learning. For each technology, a white paper offers an overview of the current status of the technology, drivers and challenges for its development and adoption, and future outlook. The white papers also include vignettes, i.e. short stories with media practitioners or users of media services as the main characters, aiming to vividly showcase how AI innovations could help the media industry in practice.
Main AI applications for the media sector. Based on the results of the state of the art analysis, we highlight the potential of specific AI applications to benefit the media industry, including multimodal knowledge representation and retrieval, media summarisation, automatic content creation, affective analysis, NLP-enabled applications, and content moderation. Similarly to the above, a short white paper is presented for each application, offering a clear overview of the current status of the technology, drivers and challenges for its development and adoption, and future outlook.
Future of AI in different media sectors. We present a collection of white papers, focusing on the deployment of AI in different media industry sectors, including news, social media, film/TV, games, music and publishing. We also explore the use of AI to address critical societal phenomena such as disinformation and to enhance the online political debate. Finally, we explore how AI can help the study of media itself in the form of AI-enabled social science tools. These papers offer an in-depth look at the current status of each sector with regard to AI adoption, most impactful AI applications, main challenges encountered, and future outlook.
Analysis of future trends for trustworthy AI. We present four white papers focusing on different aspects of trustworthy AI, namely AI robustness, AI explainability, AI fairness, and AI privacy, with a focus on media sector applications. The analysis explains existing trustworthy AI limitations and potential negative impacts.
AI datasets and benchmarks. We analyse existing AI datasets and benchmark competitions, discussing current status, research challenges and future outlook, while also providing insights on the ethical and legal aspects of the availability of quality data for AI research.
AI democratisation. We discuss issues related to AI democratisation, focusing on open repositories for AI algorithms and data and research in the direction of integrated intelligence, i.e. AI modules that could be easily integrated into other applications to provide AI-enabled functionalities.
External forces that could shape the future. We discuss the forces that could shape the future of the use of AI in the media sector, focusing on legislation/ regulation, the pandemic and its impact, and the climate crisis.
The Roadmap has been developed as part of the AI4Media public deliverable D2.3 “AI technologies and applications in media: State of Play, Foresight, and Research Directions”.
Access the full version of Roadmap
Access the Web version of Roadmap
Author: Filareti Tsalakanidou, (Information Technologies
Institute – Centre for Research and Technology Hellas)











 AI Support Needed to Counteract Disinformation
AI Support Needed to Counteract Disinformation AI for News. The smart news assistant
AI for News. The smart news assistant AI in Vision: High Quality Video Production and Content Automation
AI in Vision: High Quality Video Production and Content Automation






